This post is the first in a series of articles that will be devoted to explaining the Ushahidi Platform at a technical level for programmers and deployers.
One of the fundamental changes in version 3 of the Ushahidi Platform is a movement towards “clean architecture”. The concept of design patterns and system design has been part of programming for over 40 years, but many projects, both open and closed source, fail to completely realize the benefits of a complete architecture.
For years, very smart engineers such as Uncle Bob (Robert Martin) and Martin Fowler have been talking about the benefits of architecture and design patterns, from both the programming and business perspectives. On the programming side, the benefits of design patterns are widely recognized, from Model View Controller (MVC) to Dependency Injection (DI), techniques that programmers will instantly understand and be able to adapt to. From the business side, a well defined architecture allows for rapid prototyping and adaptation of the product to specific customer needs.
The problem is that following some design patterns does not automatically provide an architecture. MVC is a pattern, a technique that can be used within an overall architecture, but by itself does not provide a coherent explanation of the business needs of an application. The same is true of Decorators, Adapters, Front Controllers, Iterators, etc; the list of patterns available to programmers goes on and on. Design patterns solve particular programming problems and provide a structure for your application, but they are unable to answer any questions about how the application will be used. This is where the need for architecture arises.
The architecture of Ushahidi Platform v3 is largely inspired by Uncle Bob’s “Clean Architecture”, though the fundamental aspects of this architecture have been floating through programming history since the early 80s. The most important aspects of this architecture are well laid out by Uncle Bob, but two major benefits for the platform are:
 In this data flow, a GET request is handled by the Controller, which makes a direct call to the Repository, getting back one or more Entities, which are then formatted and delivered to the user. (It should be noted that the framework currently used with the platform is Kohana, but in these diagram it simply represents the web request.)
The data flow for a use case is significantly more complex than the direct access model because it requires crossing several “boundaries” between the core application and the various interfaces that define how the data is accessed, but only in abstract terms. (Remember that the core of the application does not contain any knowledge of the database or HTML or JSON or any other delivery details.) This data flow can be represented by the following diagram:
In this data flow, a GET request is handled by the Controller, which makes a direct call to the Repository, getting back one or more Entities, which are then formatted and delivered to the user. (It should be noted that the framework currently used with the platform is Kohana, but in these diagram it simply represents the web request.)
The data flow for a use case is significantly more complex than the direct access model because it requires crossing several “boundaries” between the core application and the various interfaces that define how the data is accessed, but only in abstract terms. (Remember that the core of the application does not contain any knowledge of the database or HTML or JSON or any other delivery details.) This data flow can be represented by the following diagram:
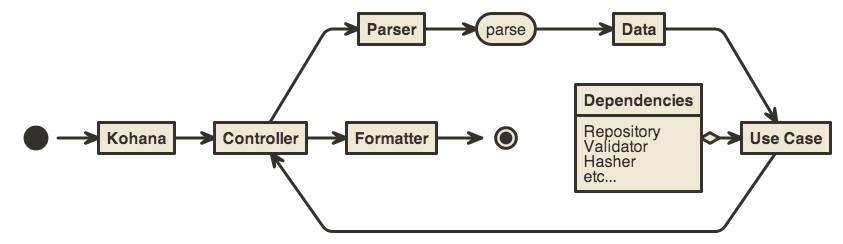 Here, a POST or PUT or DELETE request is handled by the Controller, which uses a service locator (and dependency injection) to parse the request into a data transfer object that carries the necessary request information into the application, where it is read by the use case, validated, persisted through the repository, and the resulting entity is passed back to the controller for delivery. The repository interface is specified in the application and implemented in the delivery layer, which ensures that the core application is completely database agnostic and can be tested without any persistence. Finally, the entity that was affected by the request is formatted and returned to the user.
Hopefully this post helps illuminate the architecture of the platform. The next article in this series will discuss the various types of objects within the system and the role that each plays in helping to enforce SOLID principles.
Want to get involved? We can use help with some wishlist features and with general bug reporting. Please read the getting involved wiki page for more information on our current community opportunities and have a look at our workboard on Phabricator. If you just want to chat about the platform or architecture, Woody is often available via IRC, in the #ushahidi and #cleancode channels on irc.freenode.net.
Here, a POST or PUT or DELETE request is handled by the Controller, which uses a service locator (and dependency injection) to parse the request into a data transfer object that carries the necessary request information into the application, where it is read by the use case, validated, persisted through the repository, and the resulting entity is passed back to the controller for delivery. The repository interface is specified in the application and implemented in the delivery layer, which ensures that the core application is completely database agnostic and can be tested without any persistence. Finally, the entity that was affected by the request is formatted and returned to the user.
Hopefully this post helps illuminate the architecture of the platform. The next article in this series will discuss the various types of objects within the system and the role that each plays in helping to enforce SOLID principles.
Want to get involved? We can use help with some wishlist features and with general bug reporting. Please read the getting involved wiki page for more information on our current community opportunities and have a look at our workboard on Phabricator. If you just want to chat about the platform or architecture, Woody is often available via IRC, in the #ushahidi and #cleancode channels on irc.freenode.net.
- Highly testable code. v3 includes a very high degree of test coverage, including specification tests, unit tests, and feature tests. Each of these are integrated into the development process in various ways and are part of our continuous integration. Adding new features to the platform is done through BDD techniques.
- Separation of concerns. The core of the application, the use cases and interfaces that define how the platform works at the lowest level, have no dependencies except itself. This allows for delivery aspects, such as the database implementation, or the web UI, to be completely replaced without altering the logic of platform. This is largely supported by attempting to follow SOLID principles.
In this data flow, a GET request is handled by the Controller, which makes a direct call to the Repository, getting back one or more Entities, which are then formatted and delivered to the user. (It should be noted that the framework currently used with the platform is Kohana, but in these diagram it simply represents the web request.)
The data flow for a use case is significantly more complex than the direct access model because it requires crossing several “boundaries” between the core application and the various interfaces that define how the data is accessed, but only in abstract terms. (Remember that the core of the application does not contain any knowledge of the database or HTML or JSON or any other delivery details.) This data flow can be represented by the following diagram:
Here, a POST or PUT or DELETE request is handled by the Controller, which uses a service locator (and dependency injection) to parse the request into a data transfer object that carries the necessary request information into the application, where it is read by the use case, validated, persisted through the repository, and the resulting entity is passed back to the controller for delivery. The repository interface is specified in the application and implemented in the delivery layer, which ensures that the core application is completely database agnostic and can be tested without any persistence. Finally, the entity that was affected by the request is formatted and returned to the user.
Hopefully this post helps illuminate the architecture of the platform. The next article in this series will discuss the various types of objects within the system and the role that each plays in helping to enforce SOLID principles.
Want to get involved? We can use help with some wishlist features and with general bug reporting. Please read the getting involved wiki page for more information on our current community opportunities and have a look at our workboard on Phabricator. If you just want to chat about the platform or architecture, Woody is often available via IRC, in the #ushahidi and #cleancode channels on irc.freenode.net.